数据模型眼中的2026世界杯K组格局
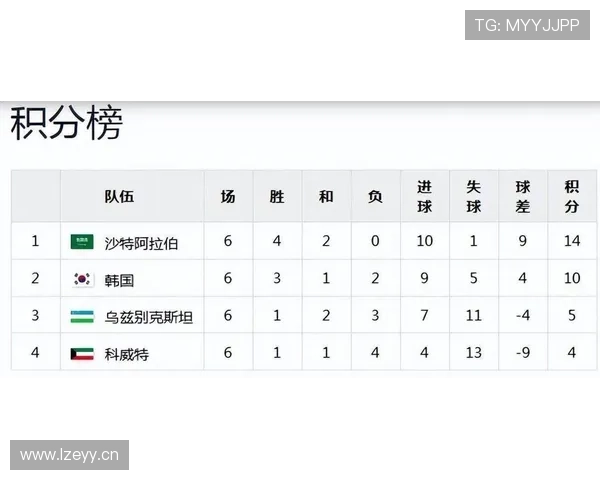
随着2026年世界杯扩军至48队,K组的构成——葡萄牙、哥伦比亚、乌兹别克斯坦以及另一支通过附加赛突围的球队——为数据建模带来了全新变量。传统强队与新兴力量的碰撞,使得预测不再仅依赖历史战绩,而需融合更动态的指标体系。
当前主流预测模型普遍将葡萄牙列为小组头名最大热门。C罗虽已过巅峰,但B费、莱奥、菲利克斯等中生代核心正值黄金期,叠加欧国联冠军带来的战术磨合优势,其预期进球(xG)与控球转化率在模拟中稳居组ued官网内首位。值得注意的是,模型对葡萄牙的隐患同样敏感:若遭遇高位逼抢型对手,后场出球稳定性可能成为被攻击的薄弱环节。
哥伦比亚的变数在于新老交替的完成度。J罗的经验与巴尔加斯、莱尔马等新生代的冲击力形成互补,但模型显示其防守端存在明显波动——近12场预选赛有7场失球超过1个。数据模拟中,哥伦比亚约有58%概率以第二身份出线,但若首战负于葡萄牙,晋级概率将骤降至31%。
乌兹别克斯坦作为亚洲技术流新锐,是模型中最难量化的一环。其U23亚洲杯夺冠班底展现的高压逼抢与快速转换,在友谊赛中曾逼平韩国。然而面对欧洲、南美强队时,身体对抗与关键球处理能力的数据短板显著。多数模型给予其12%-15%的小组出线概率,但若能利用气候适应性(假设比赛在北美较热赛区进行)和定位球战术制造冷门,可能重演2002年塞内加尔式的黑马奇迹。

值得警惕的是,所有模型均强调赛程顺序的关键影响。例如若葡萄牙首战意外受阻,而哥伦比亚与乌兹别克斯坦战成平局,末轮可能出现三队同分的极端局面。此时净胜球、进球数甚至公平竞赛积分将成为决定性因子——这恰恰是纯数据模型难以完全捕捉的人性化变量。